... this page is part of the Web Site of George North ...
Manetho:
Transparent Rollback-Recovery
with Low Overhead, Limited Rollback,
and Fast Output Commit
(IEEE Transactions on Computers, Vol. 41, No. 5, May 1992)
CSCI 6990, Fall 1995
November 27, 1995
A presentation by:
Qing Yang
Venudhar Venumuddula
George North

A short history

Egyptian Historian: Manetho
- Egypt had no exact system of time:
events were date by reign of Kings
- Lists of events were maintained at
various temples throughout Egypt
- Egyptian empire declined
- Manetho collected the lists and constructed the history of Egypt
- No global clock
- Each process maintains information
about its perception of the system's
execution history
- Process failure occurs
- A protocol collects fragments of the
system's execution history, restores
the full history of the system.
- This history is used to recover from
the failure ...
Just like the priest Manetho ... did for Egypt
Distributed Systems is direction of computing's future ... Fault Tolerance
and Recovery are a must
Requirements are: high availability, low overhead and transparency.
Applications programs written for this model CANNOT make assumptions
about ...
-- network complexity
-- failure modes of distributed systems
a Distributed Operating System (DOS) is needed
Manetho:
Transparent Rollback-Recovery
with Low Overhead, Limited Rollback,
and Fast Output Commit
DOS performance considerations are:
-- high performance during failure-free
operation
-- low-overhead fault tolerance
-- fast output commit
Manetho addresses these problems by:
-- Asynchronous message logging
(most of the time)
-- Limited rollback, only failed process
need be rolled back
-- Messages sent to the outside world without
multihost coordination Rollback-Recovery Methods
Pessimistic message logging
-- Synchronously logging recovery information on stable store
-- Processes that survive failure are not rolled back
-- No latency in sending message to outside world
Optimistic message logging
-- Asynchronously logging recovery information
-- Processes that survive failure may need to roll back
-- Output latency is high because of multihost coordination Rollback-Recovery
Methods
Consistent check pointing
-- No message logging, processes must coordinate taking checkpoints
-- Processes that survive failure may need to roll back
-- May or may not require multihost coordination
Manetho attempts to combine the best these methods ... using
-- Independent (or Consistent) check pointing
-- Sender-based volatile (optimistic) message logging (most of the time)
-- Antecedence Graph which records the "happened before"
relationship
-- Only failed processes need rollback and only to the most recent checkpoint
-- Output commit without multihost coordination Independent or Consistent
Check pointing
Originally Manetho used Independent check pointing
Later designs implemented consistent check pointing
Studies comparing these methods have shown that the overhead is about the
same
This result is is due to the fact that check pointing costs are dominated
by writing to stable storage
Costs for synchronizing checkpoints is negligible in comparison
Manetho's garbage collection problem is simplified by using consistent checkpoints
Manetho Terminology
Recovery Units (RU's) ...
a distributed system consists of a number of RU's that communicate only
through messages. RU is the unit of failure and recovery. It can correspond
to a process, a machine, or any unit of failure.
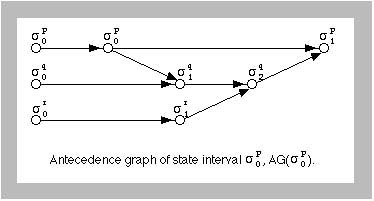
Antecedence Graph ...
is a data structure that tracks nondeterministic events. In Manetho, it
maintains the invariant that no RU is affected by failures that occur in
other RU's. It is a key property of Manetho.
Output commit ...
is the process needed to communicate with the outside world (any entity
that cannot rollback its state after a failure). Manetho Terminology
Nondeterministic Events ...
-- Creation of an RU
-- Message receipt from another RU
-- Input to RU from the outside world
-- Internal event such as thread synchronization
-- etc.
-- delimit State Intervals
State Intervals ...

Assumptions
1. RU's do not have access to common time or synchronized clocks. (No shared
memory).
2. RU's are fail-stop. An RU fails by losing its volatile state and destroying
its threads without transmitting incorrect messages.
3. Each message has a unique identifier, generated deterministicly.
4. Communications subsystems is assumed to be unreliable and asynchronous.
A message may be lost, duplicated, or arbitrarily delayed. Corrupted messages
are detectable. The network is immune to partition.
5. Each RU has access to highly-available stable storage that survives failures.
6. Each RU has a system-wide unique identifier. A lis of functioning RU's
is maintained.
7. RU execution is sequential, multi-treaded, picewise deterministice intervals.
Each interval is started by a non-deterministic event.